Finding a duplicate lines from a file is not a hard problem. But sometime in an interview question, folks sometimes get very confused about the method they have to use.
In this tutorial we will go over steps on how to remove duplicates from a CSV file and any other file.
Let’s get started:
Step-1.
Create file CrunchifyFindDuplicateCSV.java
Step-2.
- Put below code into file.
- We are using BufferedReader to read files.
- One by by add lines to HashSet.
- Use method add() to check if line already present in Set or not.
- Adds the specified element to this set if it is not already present. More formally, adds the specified element e to this set if this set contains no element e2 such that Objects.equals(e, e2). If this set already contains the element, the call leaves the set unchanged and
returns false.
- Adds the specified element to this set if it is not already present. More formally, adds the specified element e to this set if this set contains no element e2 such that Objects.equals(e, e2). If this set already contains the element, the call leaves the set unchanged and
- Once skipped, we will print that line as a skipped line.
crunchify.csv file
name city number age kedar kapan 9843875 23 sedai ktm 97798433 23 ayush kalopul 9856324 12 dipal ratopul 9842567 34 malla setiopul 1258496 33 ayush kalopul 9856324 12 babin karki hariyopul 32589 11 raju dhading 58432 44 sedai ktm 97798433 23 Crunchify, LLC PayPal.com Google.com Twitter.com FaceBook.com Crunchify, LLC Google.com Visa.com MasterCard.com Citi.com California Austin California
CrunchifyFindDuplicateCSV.java
package crunchify.com.tutorial;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashSet;
/**
* @author Crunchify.com
* How to Remove Duplicate Elements from CSV file in Java?
*/
public class CrunchifyFindDuplicateCSV {
public static void main(String[] argv) {
String crunchifyCSVFile = "/Users/Shared/crunchify.csv";
// Reads text from a character-input stream, buffering characters so as to provide for the
// efficient reading of characters, arrays, and lines.
BufferedReader crunchifyBufferReader = null;
String crunchifyLine = "";
// This class implements the Set interface, backed by a hash table (actually a HashMap instance).
// It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will
// remain constant over time. This class permits the null element.
HashSet<String> crunchifyAllLines = new HashSet<>();
try {
crunchifyBufferReader = new BufferedReader(new FileReader(crunchifyCSVFile));
while ((crunchifyLine = crunchifyBufferReader.readLine()) != null) {
if (crunchifyAllLines.add(crunchifyLine)) {
crunchifyLog("Processed line: " + crunchifyLine);
} else if (!crunchifyIsNullOrEmpty(crunchifyLine)) {
crunchifyLog("--------------- Skipped line: " + crunchifyLine);
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (crunchifyBufferReader != null) {
try {
crunchifyBufferReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
// Check if String with spaces is Empty or Null
public static boolean crunchifyIsNullOrEmpty(String crunchifyString) {
if (crunchifyString != null && !crunchifyString.trim().isEmpty())
return false;
return true;
}
// Simple method for system outs
private static void crunchifyLog(String s) {
System.out.println(s);
}
}
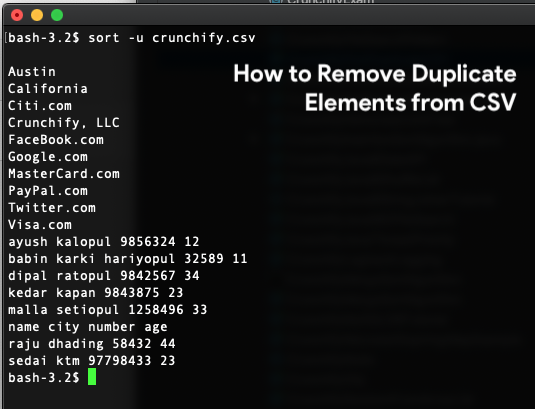
// Linux command to remove duplicate lines from file:
// $ sort -u /Users/Shared/crunchify.csv
Let’s run Java program in IntelliJ IDE.
Here is a result:
Processed line: name city number age Processed line: kedar kapan 9843875 23 Processed line: sedai ktm 97798433 23 Processed line: ayush kalopul 9856324 12 Processed line: dipal ratopul 9842567 34 Processed line: malla setiopul 1258496 33 --------------- Skipped line: ayush kalopul 9856324 12 Processed line: babin karki hariyopul 32589 11 Processed line: raju dhading 58432 44 --------------- Skipped line: sedai ktm 97798433 23 Processed line: Processed line: Crunchify, LLC Processed line: PayPal.com Processed line: Google.com Processed line: Twitter.com Processed line: FaceBook.com --------------- Skipped line: Crunchify, LLC --------------- Skipped line: Google.com Processed line: Visa.com Processed line: MasterCard.com Processed line: Citi.com Processed line: California Processed line: Austin --------------- Skipped line: California Process finished with exit code 0
Hope you find this Java program useful find duplicate lines in CSV or any other file.
How to find duplicate lines in CSV using Linux command?
$ sort -u /Users/Shared/crunchify.csv
Result: