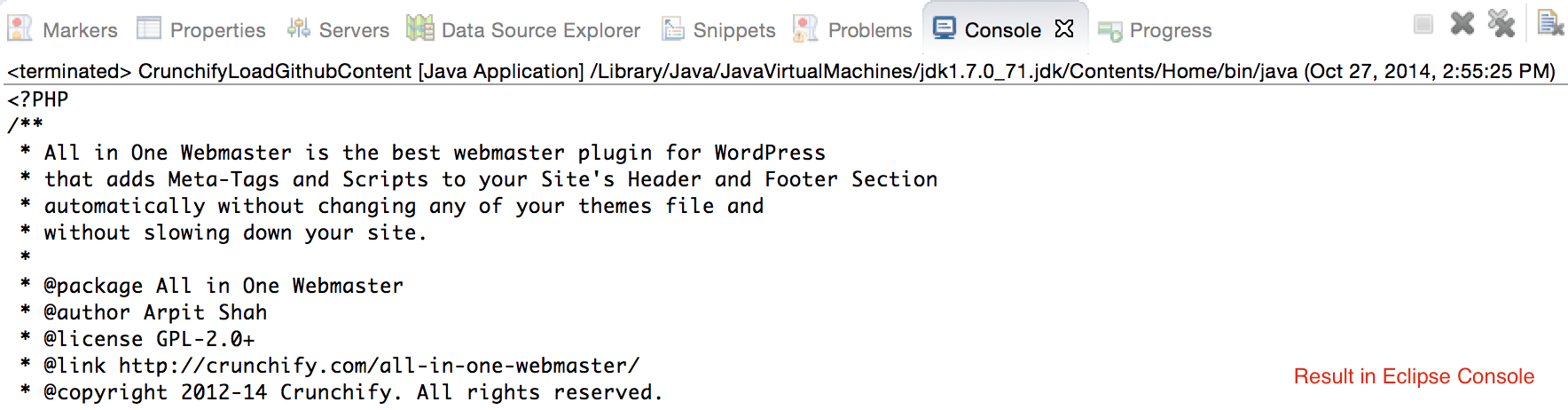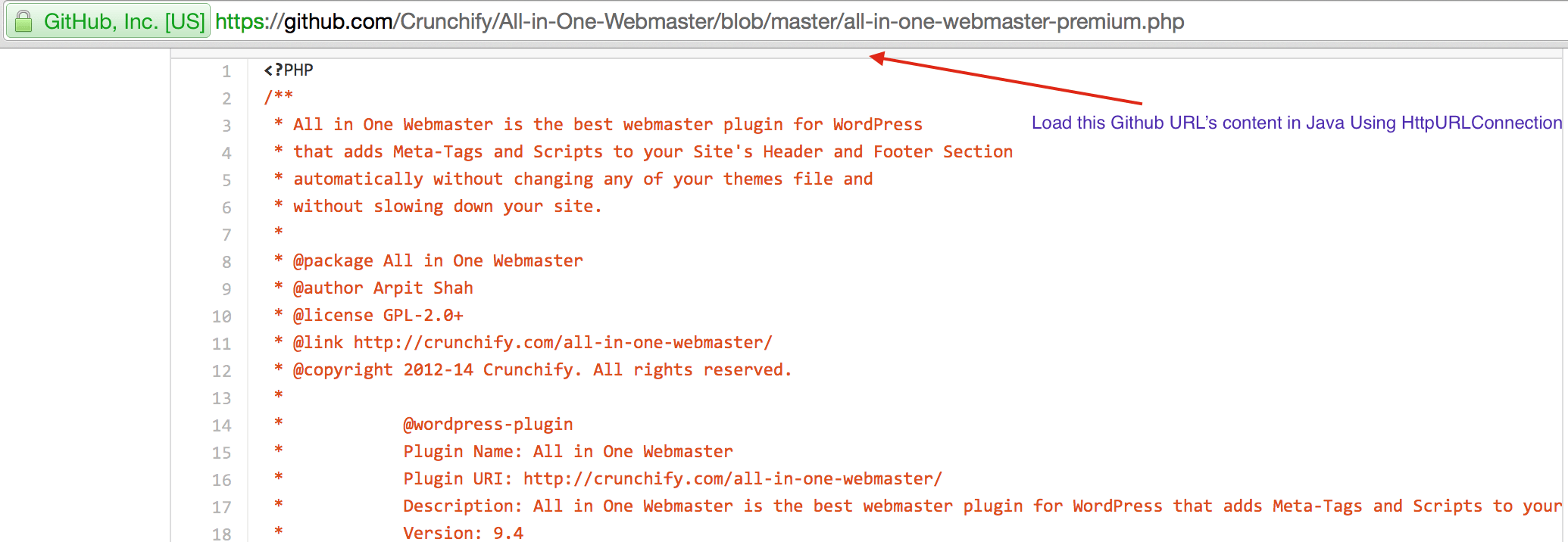
In this Java Tutorial we will go over steps to retrieve GitHub URL content using HttpURLConnection. In other words below is a Java API to get a file content from GitHub.
Each HttpURLConnection instance is used to make a single request but the underlying network connection to the HTTP server may be transparently shared by other instances. getHeaderFields() Returns an unmodifiable Map of the header fields. The Map keys are Strings that represent the response-header field names. Each Map value is an unmodifiable List of Strings that represents the corresponding field values.
Now let’s get started:
- Create class
CrunchifyLoadGithubContent.java - We will download contents: https://raw.githubusercontent.com/Crunchify/wp-super-cache/master/wp-cache.php (from plugin: WP Super Cache Github Repo)
- Get all Header Fields using getHeaderFields() API. We need this to find out if above URL or any other URL is getting redirected or not? Note: This is totally optional. In case of HTTP 301 and HTTP 302 redirection this will help.
- Create API
crunchifyGetStringFromStream(InputStream crunchifyStream)to convert Stream to String. - Print the same output to Console.
NOTE: HTTP Status 301 means that the resource (page) is moved permanently to a new location. 302 is that he requested resource resides temporarily under a different URI. Mostly 301 vs 302 is important for indexing in search engines as their crawlers take this in account and transfer page rank when using 301.
Also, there is an assumption that – GitHub URL needs to be public.
package crunchify.com.tutorial;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.io.StringWriter;
import java.io.Writer;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.List;
import java.util.Map;
/**
* @author Crunchify.com
*
*/
public class CrunchifyLoadGithubContent {
public static void main(String[] args) throws Throwable {
String link = "https://raw.githubusercontent.com/Crunchify/All-in-One-Webmaster/master/all-in-one-webmaster-premium.php";
URL crunchifyUrl = new URL(link);
HttpURLConnection crunchifyHttp = (HttpURLConnection) crunchifyUrl.openConnection();
Map<String, List<String>> crunchifyHeader = crunchifyHttp.getHeaderFields();
// If URL is getting 301 and 302 redirection HTTP code then get new URL link.
// This below for loop is totally optional if you are sure that your URL is not getting redirected to anywhere
for (String header : crunchifyHeader.get(null)) {
if (header.contains(" 302 ") || header.contains(" 301 ")) {
link = crunchifyHeader.get("Location").get(0);
crunchifyUrl = new URL(link);
crunchifyHttp = (HttpURLConnection) crunchifyUrl.openConnection();
crunchifyHeader = crunchifyHttp.getHeaderFields();
}
}
InputStream crunchifyStream = crunchifyHttp.getInputStream();
String crunchifyResponse = crunchifyGetStringFromStream(crunchifyStream);
System.out.println(crunchifyResponse);
}
// ConvertStreamToString() Utility - we name it as crunchifyGetStringFromStream()
private static String crunchifyGetStringFromStream(InputStream crunchifyStream) throws IOException {
if (crunchifyStream != null) {
Writer crunchifyWriter = new StringWriter();
char[] crunchifyBuffer = new char[2048];
try {
Reader crunchifyReader = new BufferedReader(new InputStreamReader(crunchifyStream, "UTF-8"));
int counter;
while ((counter = crunchifyReader.read(crunchifyBuffer)) != -1) {
crunchifyWriter.write(crunchifyBuffer, 0, counter);
}
} finally {
crunchifyStream.close();
}
return crunchifyWriter.toString();
} else {
return "No Contents";
}
}
}
While debugging I got this as a part of crunchifyHeader value. Also, this tutorial applies to Bitbucket public repo also.
{
null=[
HTTP/1.1200OK // this is what we are checking in above for loop. If 301 or 302 then get new URL.
],
X-Cache-Hits=[
1
],
ETag=[
"94a3eb8b3b5505f746aa8530667969673a8e182d"
],
Content-Length=[
24436
],
X-XSS-Protection=[
1;mode=block
],
Expires=[
Mon,
27Oct201420: 00: 31GMT
],
X-Served-By=[
cache-dfw1825-DFW
],
Source-Age=[
14
],
Connection=[
Keep-Alive
],
Server=[
Apache
],
X-Cache=[
HIT
],
Cache-Control=[
max-age=300
],
X-Content-Type-Options=[
nosniff
],
X-Frame-Options=[
deny
],
Strict-Transport-Security=[
max-age=31536000
],
Vary=[
Authorization,
Accept-Encoding
],
Access-Control-Allow-Origin=[
https: //render.githubusercontent.com
],
Date=[
Mon,
27Oct201419: 55: 31GMT
],
Via=[
1.1varnish
],
Keep-Alive=[
timeout=10,
max=50
],
Accept-Ranges=[
bytes
],
Content-Type=[
text/plain;charset=utf-8
],
Content-Security-Policy=[
default-src'none'
]
}