Sometime back I’ve written a tutorial on How to Write XML DOM into File using Java? It’s very simple tutorial with actual real use-case.
Last week while working on similar XML and Java issue – I’ve created a solution which gets a XML result from 3rd party URL as a String and then parse the same XML document using Java XML XPath Parser.
I used javax.xml.parsers to scan through XML DOM and was able to get specific XML element value very quickly.
XPath provides syntax to define part of an XML document.
You may need below Maven Dependency in your project.
<dependency> <groupId>javax.xml</groupId> <artifactId>jaxp-api</artifactId> <version>1.4.2</version> </dependency>
If you have any of below questions then you are right location:
- XML XPath Tutorial. XPath Parsing XML in Java
- Java XPath Parser – Parse XML Document
- javax.xml.xpath tutorial
- javax.xml.parsers tutorial
- How to work with xpaths in java (with examples)
- Parsing an XML Document with XPath
Let’s get started:
Steps:
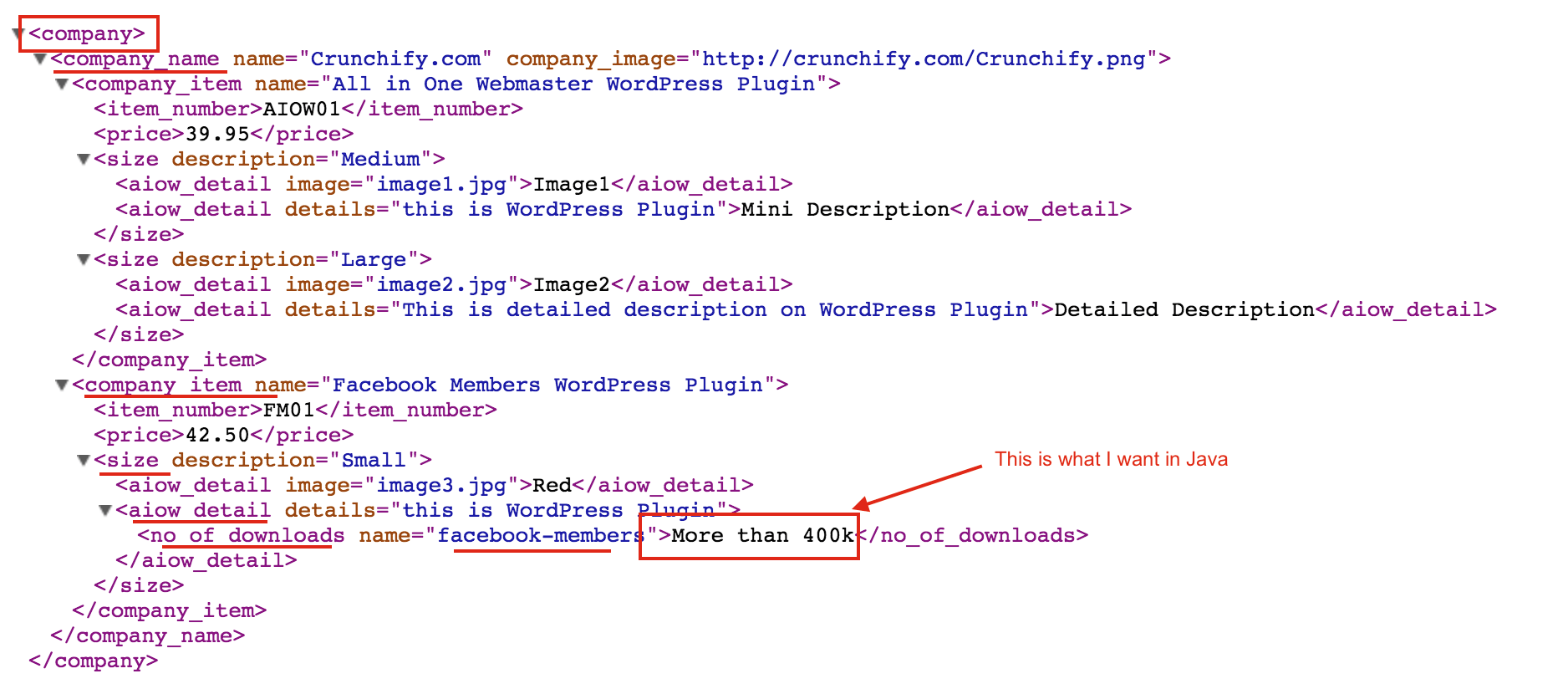
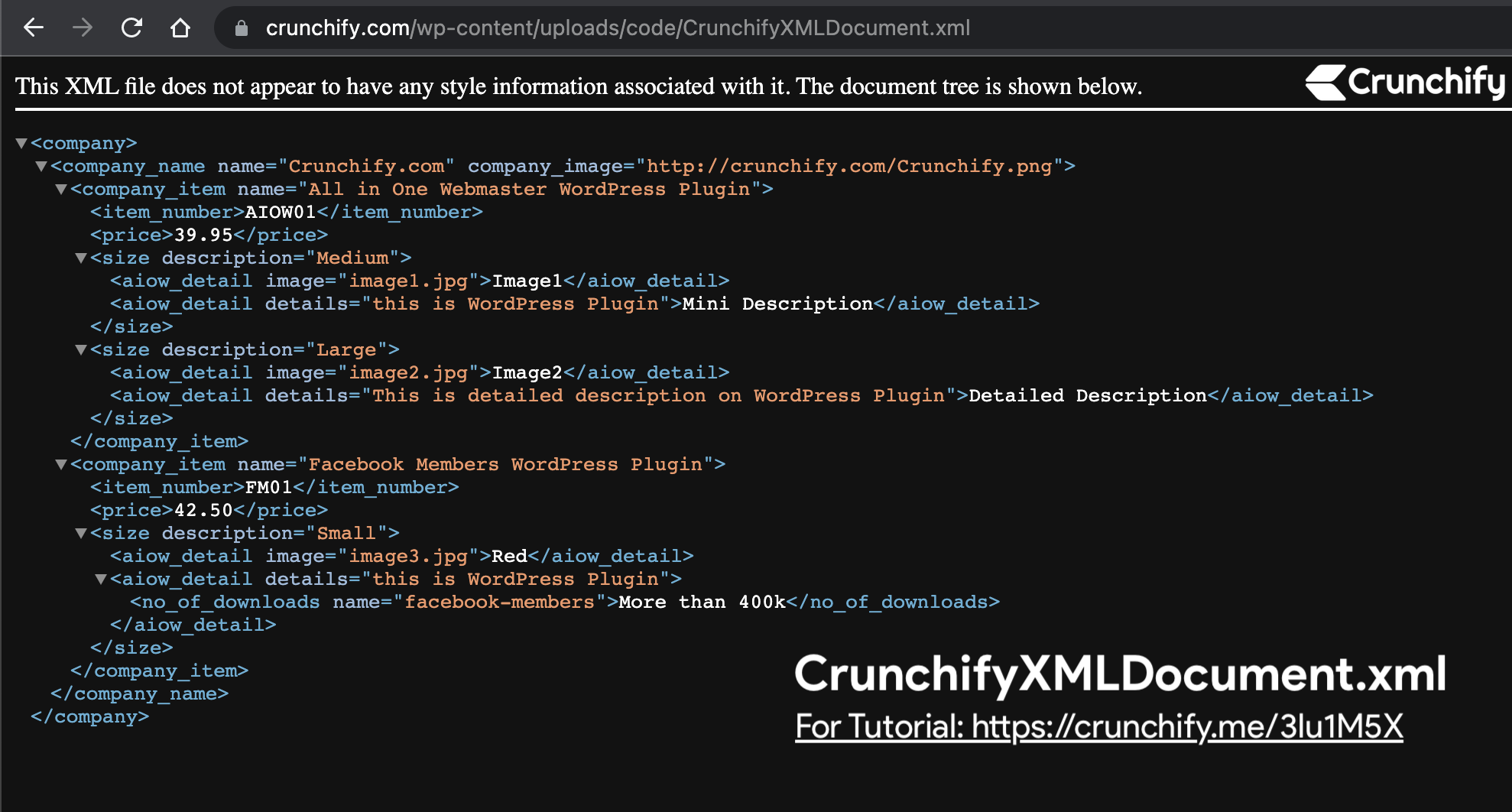
- I’ll using this XML document: https://crunchify.com/wp-content/uploads/code/CrunchifyXMLDocument.xml
- I’ll fetch XML document using
crunchifyGetURLContents(String url)API. - We will use XPathExpression.evaluate to get access to compiled XPath expressions. XPathExpression is a query language to select part of the XML document based on the query String.
- Using XPath Expressions, we can find nodes in any xml document satisfying the query string.
- javax.xml.xpath.XPathExpression.evaluate evaluates the compiled XPath expression in the specified context and return the result as the specified type, i.e.
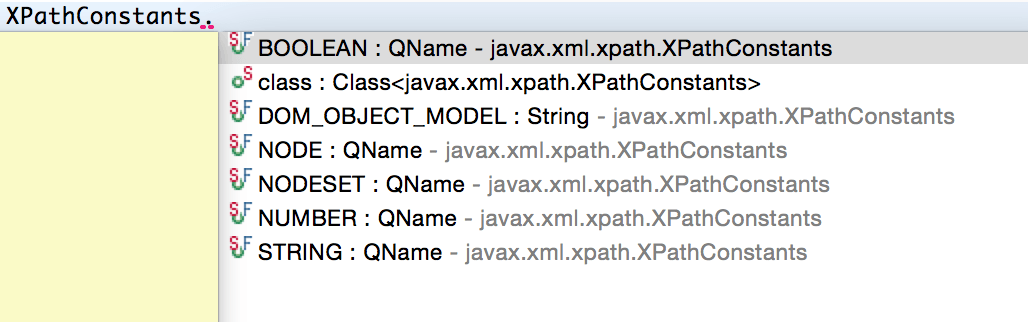
XPathConstants.STRING
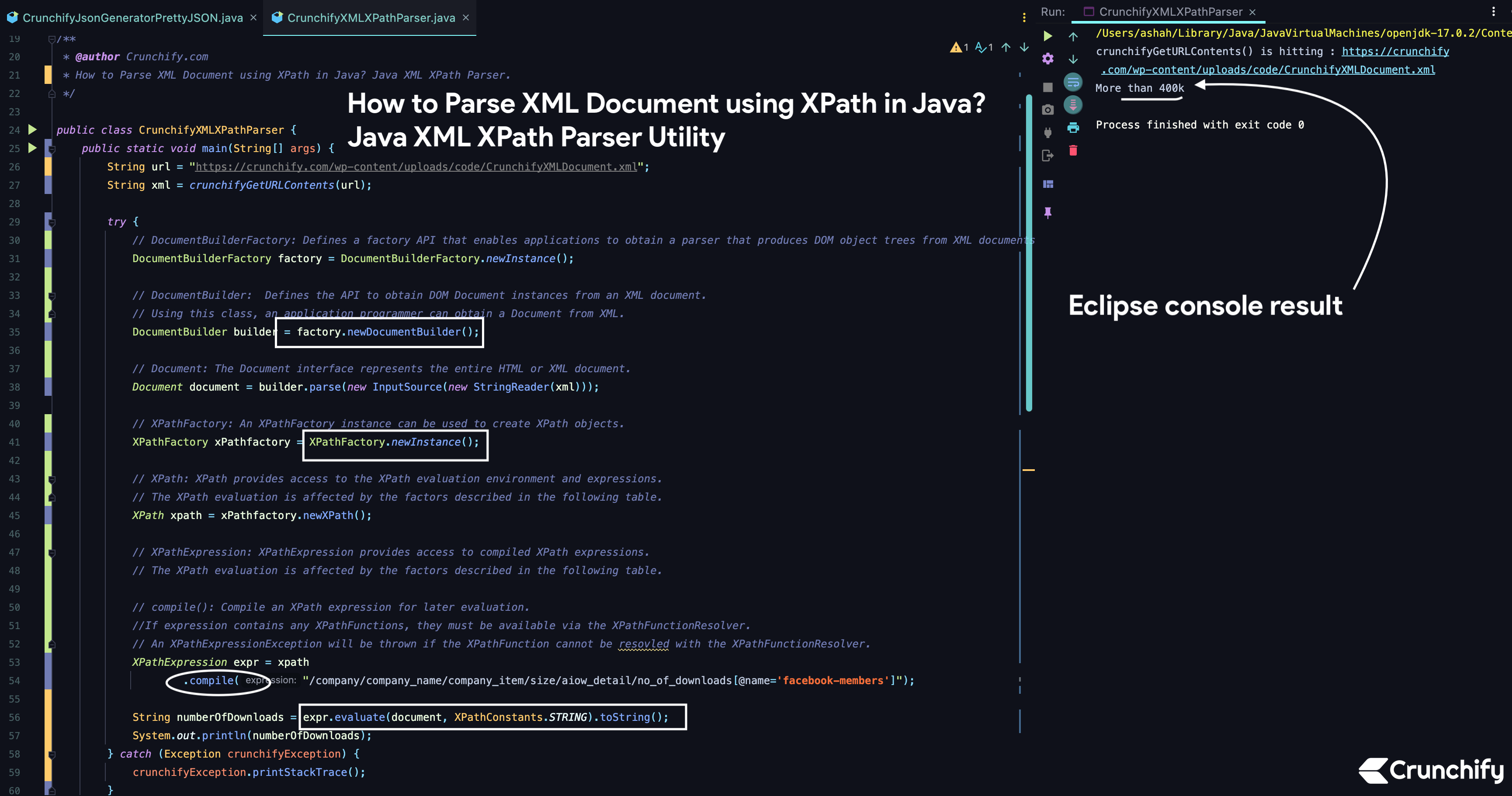
CrunchifyXMLXPathParser.java
package crunchify.com.tutorials;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.net.URL;
import java.net.URLConnection;
import java.nio.charset.Charset;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.xml.sax.InputSource;
/**
* @author Crunchify.com
*
*/
public class CrunchifyXMLXPathParser {
public static void main(String[] args) {
String url = "https://crunchify.com/wp-content/uploads/code/CrunchifyXMLDocument.xml";
String xml = crunchifyGetURLContents(url);
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new InputSource(new StringReader(xml)));
XPathFactory xPathfactory = XPathFactory.newInstance();
XPath xpath = xPathfactory.newXPath();
XPathExpression expr = xpath
.compile("/company/company_name/company_item/size/aiow_detail/no_of_downloads[@name='facebook-members']");
String numberOfDownloads = expr.evaluate(document, XPathConstants.STRING).toString();
System.out.println(numberOfDownloads);
} catch (Exception e) {
e.printStackTrace();
}
}
public static String crunchifyGetURLContents(String myURL) {
System.out.println("crunchifyGetURLContents() is hitting : " + myURL);
StringBuilder sb = new StringBuilder();
URLConnection urlConn = null;
InputStreamReader in = null;
try {
URL url = new URL(myURL);
urlConn = url.openConnection();
if (urlConn != null)
urlConn.setReadTimeout(60 * 1000);
if (urlConn != null && urlConn.getInputStream() != null) {
in = new InputStreamReader(urlConn.getInputStream(), Charset.defaultCharset());
BufferedReader bufferedReader = new BufferedReader(in);
if (bufferedReader != null) {
int cp;
while ((cp = bufferedReader.read()) != -1) {
sb.append((char) cp);
}
bufferedReader.close();
}
}
in.close();
} catch (Exception e) {
throw new RuntimeException("Exception while calling URL:" + myURL, e);
}
return sb.toString();
}
}
Console Result:
Just run above program as a Java Application and you will see result as below.
crunchifyGetURLContents() is hitting : https://crunchify.com/wp-content/uploads/code/CrunchifyXMLDocument.xml More than 400k
Below are the supported XPathConstants ENUMs.